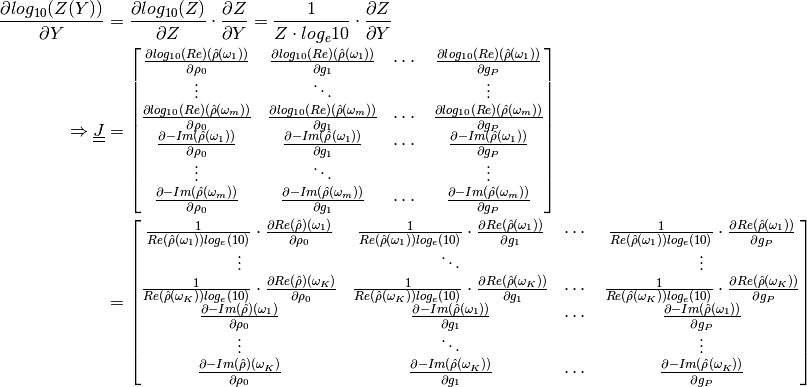Inversion and implementation details¶
Inversion¶
The forward model is formulated using the real and imaginary parts, and is a real valued function by stacking real and imaginary part on top of each other, i.e. by doubling the data space.
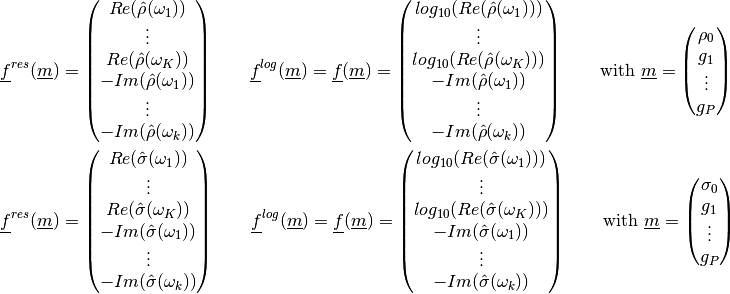
Jacobian¶
The Jacobian of  is defined as:
is defined as:
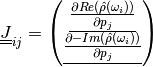
As such it is a (2 F x M) matrix, with F the number of frequencies and M the number of patameters.
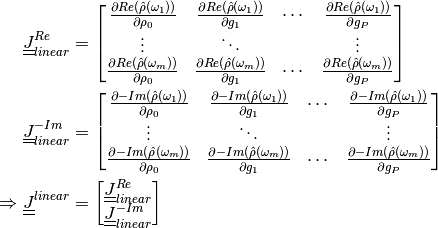
The Jacobian of 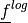 can now be computed using the chain
rule:
can now be computed using the chain
rule: